
Tetrad Database Misconfiguration Exposes 120 Million Americans
Last updated September 17, 2021

- A massive database leak left millions of American households as well as businesses exposed.
- The sets of exposed data contained information used for behavioral analytics.
- The lack of strict regulations that underpin data aggregation has resulted in increasing data leaks of this kind.
The market analysis giant “Tetrad” has misconfigured an Amazon S3 bucket containing the details of 120 million Americans, enabling anyone with a browser to access it and download the contained files. This is precisely what an UpGuard researcher did on February 3, 2020, finding three large files totaling a size of 747 gigabytes. The data appeared to derive from Tetrad’s clients, while some sets were collected by the firm for their account. Tetrad has a clientele coming from retail, restaurants, commercial real estate, healthcare, banking & finance, and more, so the range of the data exposed is pretty wide. The researcher contacted the firm repeatedly, and they finally secured the database on February 10.
Here are some examples of the exposed data that concerns businesses:
- 3.8 million loyalty card accounts belonging to Bevmo;
- 16-million-rows spreadsheet detailing purchases from TSC;
- 700,000-million-rows spreadsheet detailing online purchases made on Kate Spade's e-commerce website;
- 4,000-rows spreadsheet detailing the IBM Tririga deployment locations for Chipotle.
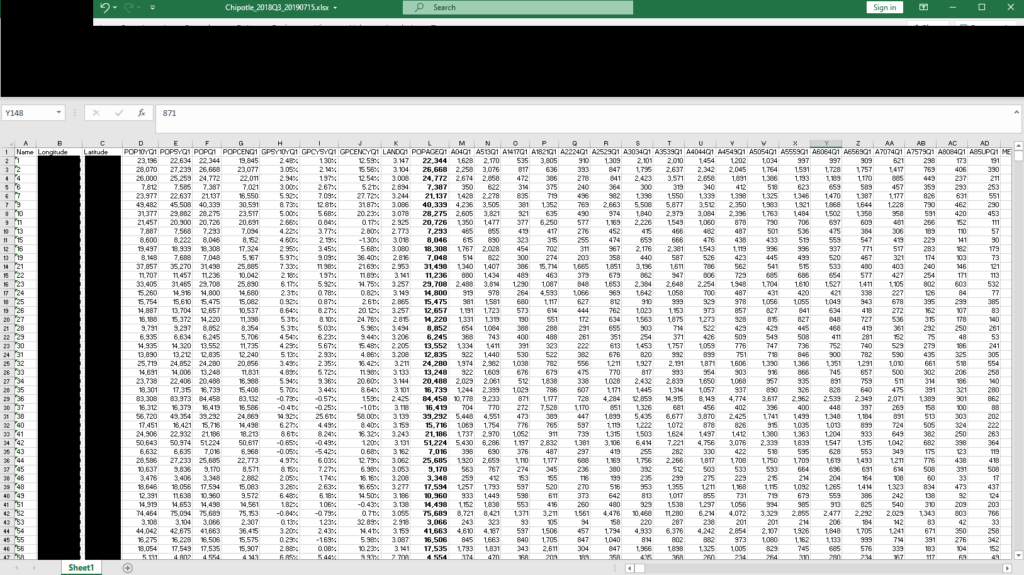
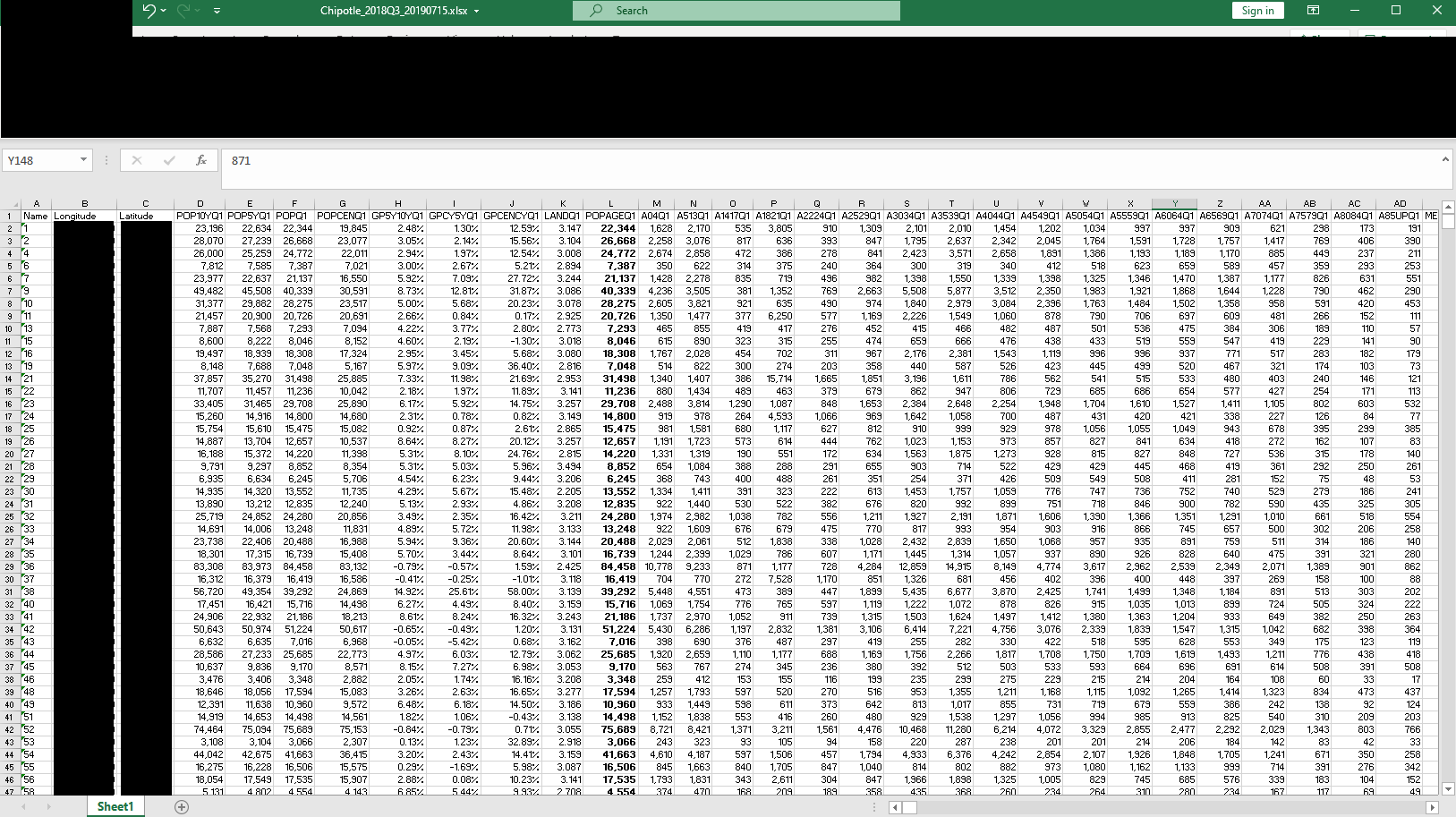
Source: UpGuard
In this vast trove of data, there was a subset labeled with the “Experian Mosaic” tag, which contained the data of 120 million American households. The information populating each entry of this set includes the name (or names) of the head(s) of the household, their gender, the physical home address, and a Mosaic group ID code.
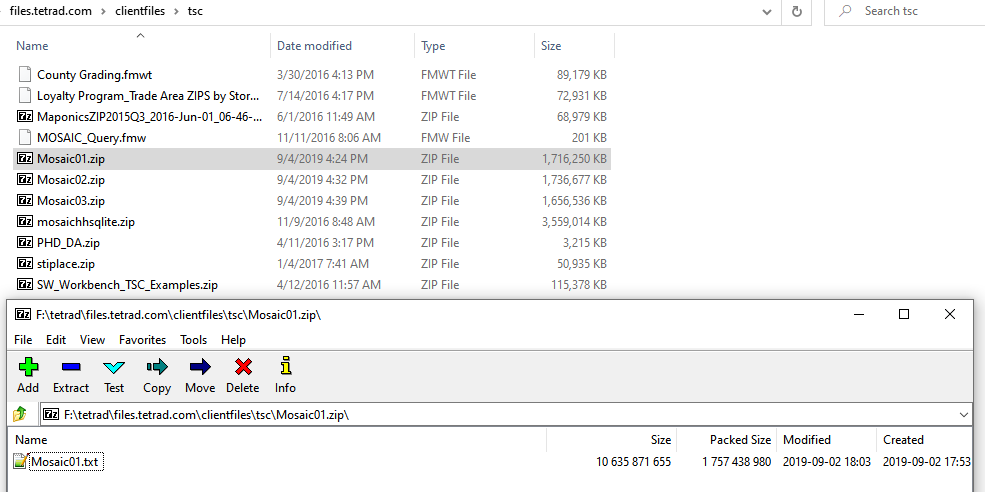
Source: UpGuard
The purpose of setting up and feeding these “data lakes” with this type of information is to enable marketers and vendors to refine the taxonomy of consumers, identify buying patterns, and correlate them with other data points. This information is then used to form social groups that pertain to specific demographics. Long story short, Tetrad classifies American households according to their purchasing power and habits and then helps businesses allocate resources for future development, i.e., open stores where the biggest spenders reside.
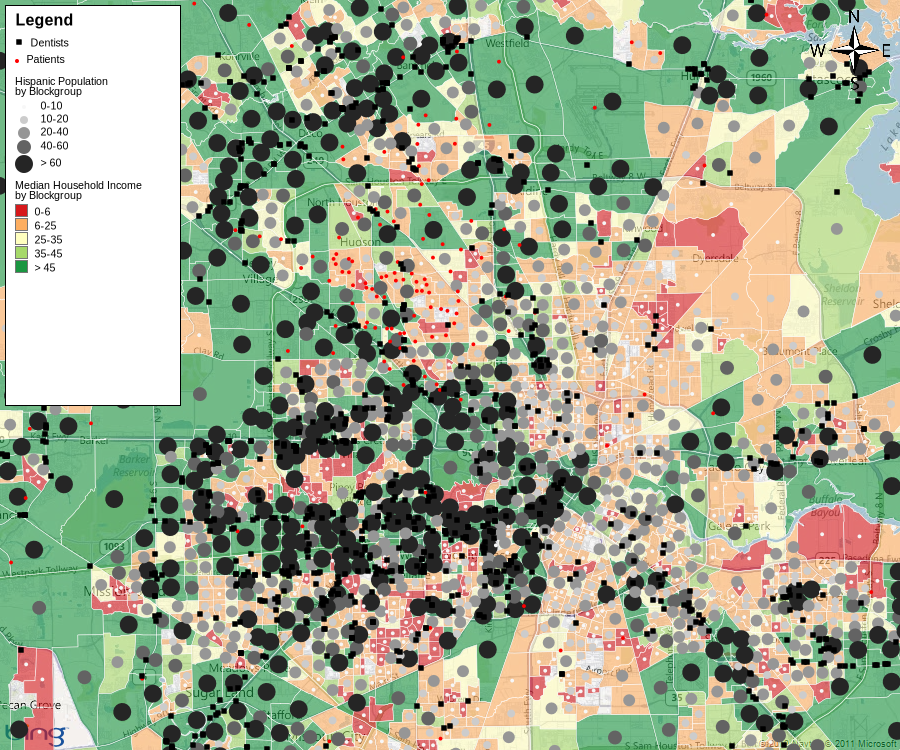
Source: UpGuard
This is yet another characteristic example of the depth and extent of data mining in the present times. People know about it, have given their consent, and in many cases, they are the direct providers of this data. However, people are unaware of the massive data trading operation that happens in the background. Neither do they know how fragments from everywhere end up together to form fully detailed profiles of citizens and households, nor how firms collaborate to de-anonymize this data by setting up a common platform where they all contribute. And finally, when all of this data is placed online, without any protection whatsoever, literally anyone gets to access it.
This is obviously well beyond the scope of any user data sharing consent that may have been given to the aggregators, so entities like the FTC should finally impose penalties that match the damage done to the people.
Related






Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular





Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular