
Data Enrichment Industry Responsible for a Massive Data Leak Affecting 1.2 Billion Individuals
Last updated September 18, 2021

- A customer of two data enrichment companies has exposed the data of around 1.2 billion people.
- The data was already available online, but its current utilization goes beyond the initial consent given by the owners.
- Aggregating from multiple sources gives new value to this data, providing ease and comfort to hackers.
Researchers Vinny Troia and Bob Diachenko discovered an unprotected Elasticsearch server containing 4 terabytes of data that corresponds to billions of user accounts. After looking deeper into it, the researchers figured that the data sets corresponded to about 1.2 billion people, exposing their names, email addresses, phone numbers, LinkedIn, and Facebook profile information. The discovery of this massive leak occurred on October 16, 2019, while the database has now been added on Troy Hunt’s HaveIBeenPwned platform, and the affected users must have received an email already.
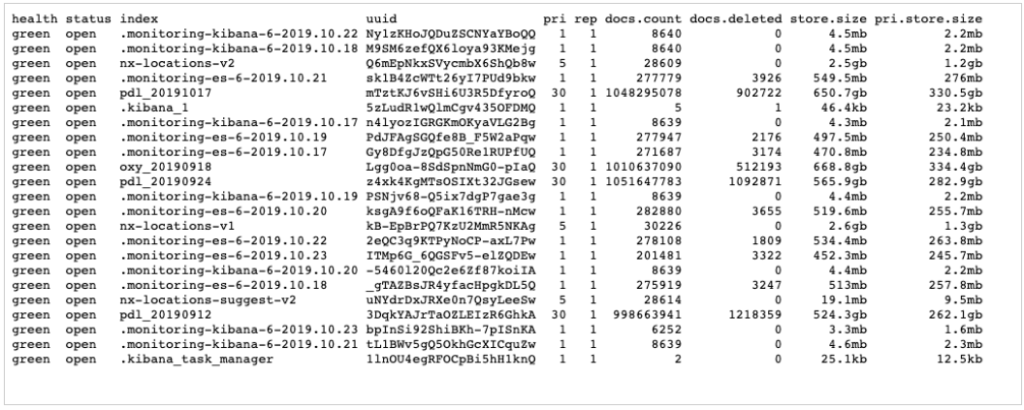
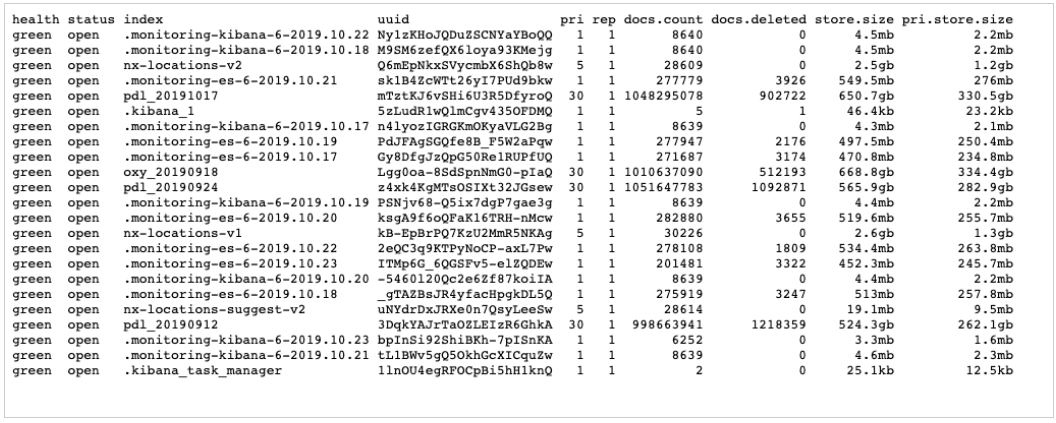
Source: Data Viper
The server that was left online without the need for a password or any authentication contained four data indexes labeled as “PDL” and “OXY”. These correspond to the data enrichment companies “People Data Labs” and “OxyData.io”. These companies help businesses in their decision making and customer engagement by collecting massive amounts of publicly available data from multiple sources, merging them into a single data set, and refining them through cleansing and analysis. That said, the exposed data wasn't private, but their combined value gives them a new character and level of worthiness.
The researchers notified PDL about the issue, and the firm responded that the server in question doesn’t belong to them. After some targeted API-based testing was carried out by the researchers, they were able to confirm that the leaked database originated from PDL. OxyData also responded by saying that the server did not belong to them either, but they didn’t offer the researchers the option to access their API for testing purposes. While the server doesn’t belong to either firm, it was one of their customers who misused this data, and this creates an unprecedented problem of attribution.
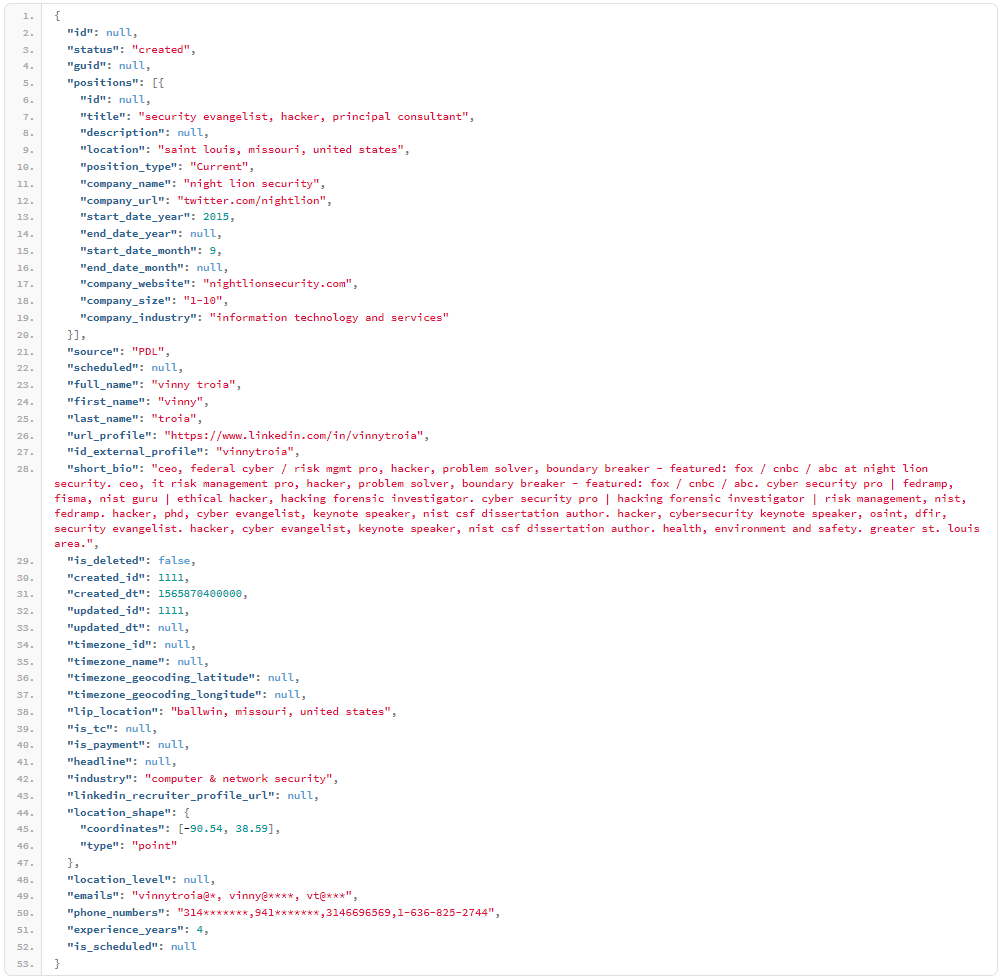
Source: Data Viper
The data enrichment companies claim that they are not accountable and that their data use policies place the responsibility of following proper data securing practices to their customers. However, they admit that they have no way to enforce these agreements, or even to thoroughly check how every single party uses the shared data. Most importantly, the exposed people who are the victims of data aggregators are never asked for additional consent, and never get to know the involved purposes anymore. The case is now in the hands of GDPR enforcing authorities, the FBI, and all national data protection agencies that should investigate and penalize the responsible parties.
Dave Farrow, Senior Director of Information Security at Barracuda Networks, shared the following comment with TechNadu: "From the perspective of the people whose information was part of this dump, this doesn’t qualify as a cut-and-dry data breach. This is an instance where a customer of a company, has exposed the intellectual property (IP) of a vendor. Users of this type of data are often on the periphery, or maybe even acting independently of their company's IT and security teams. The result can be "shadow IT" holding sensitive information that is not monitored and protected by the rest of the company's controls. It's important for all functions of a company to consider their obligations to protect data belonging to their employees, customers, and vendors, and to ensure IT and security teams know about new sources of data."
Ray Canzanese, threat research director at cloud security provider Netskope provided us with the following comment about the case: "Accidental exposure of data in the cloud continues to be one of the leading causes of data breaches. The three main causes of this are: a.) the abundance of cloud apps that make their use challenging, b.) the inability of the systems to identify user intentions and configuration mistakes, and c.) the control power that has passed into the hands of large teams of users."
Do you have anything to comment on this latest incident? Share your thoughts with us in the section down below, or on our socials, on Facebook and Twitter.
Related






Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular





Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular