
Scientists Prove Tricking Sophisticated Voice Authentication Systems Is Feasible
Last updated September 28, 2021

- Researchers proved that state-of-the-art voice verification systems can be fooled using existing tools.
- All that would be needed is a set of machine-learning algorithms and 15 minutes of the victim’s speech.
- The chances of tricking sophisticated voiceprint identification systems go as high as 93.57%.
Two researchers from the University of Waterloo have developed a novel attack against the most sophisticated voice authentication systems today, and they have found that their approach could enjoy success rates of up to 93.57%. Moreover, they have developed a way to surpass countermeasures (CMs) and challenges in the context of a telephony network attack against biometrics-supported call center defense systems.
The scientists' findings are very important for developers of automated verification systems (ASVs), as these are increasingly deployed in crucial operations such as bank transactions, so additional countermeasures need to be developed now.
Voice authentication is generally deployed in security-critical environments, protecting the owner of an account from being spoofed by malicious individuals. The developers of ASVs use voiceprints as biometrics, as these are diverse and “unique” enough to be considered a safe protective measure. The real user enrolls in a system by supplying a vocal sample and then verifies the signature to lock the match. ASVs are capable of capturing and identifying physical speech characteristics that stem from the size and shape of the larynx and the vocal tract, as well as the user’s access, speech rhythm, and pronunciation.
The researchers found out that if someone held roughly 15 minutes of speech from the victim, they could use currently available speech synthesis systems that rely upon machine learning algorithms and derive a very convincing result. Simply taking videos of the target from social media or other online platforms would be enough. Then, one could use a rooted device to bypass the microphone channel and send the audio waveforms directly into the app.
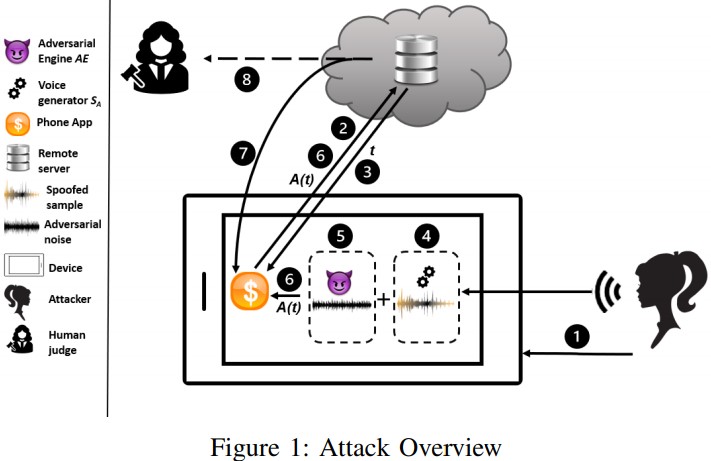
Of course, there are many factors to consider here, and not every approach has the same success rate. Generally, the more an attacker knows about what CMs are deployed by the ASV, the higher the chances of their success are.


On the over-telephone-network attacks, the scientists used the Opus (lossless) audio codec to convert a captured waveform to an encoded signal. By purposefully setting a packet loss of 2% while passing that signal through a remote data center over the internet at the university using UDP, the team could simulate a realistic telephone network jitter. Finally, the signal is decoded with “opensdec” and turned back to an audio waveform. The success rates of this approach go up to 31%.

The scientists suggest that detection systems are further enhanced by tools that can detect elements accompanying human speech such as ‘EchoVib,’ ‘VoiceGesture,’ and ‘VoiceLive.’ The deployment of these measures, though, would make the authentication process for the real users even more cumbersome. Another approach would be audio squeezing and spatial smoothing, which, again, may not be 100% effective. The best approach would be to add one more authentication method on top of the voiceprints, like facial recognition or fingerprints.
Related






Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular



Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular