
LLM Data Poisoning Risk: LLMs Can Be Poisoned by Small Samples, Research Shows
Published on October 10, 2025

- Fixed sample poisoning: Research shows a surprisingly small number of malicious documents can poison large language models.
- Backdoor flaws created: This technique can introduce flaws, where a specific trigger phrase causes the model to produce undesirable or manipulated output.
- Challenges existing assumptions: The findings challenge the belief that poisoning attacks require control over a significant percentage of training data.
A new study on LLM data poisoning found that a small, fixed number of malicious documents (as few as 250) can successfully "poison" an LLM's training data, creating hidden backdoor vulnerabilities.
This finding demonstrates that data poisoning attacks may be more practical and scalable than previously understood, posing new AI security risks.
Model Size and Poisoning Effectiveness
Recent Anthropic research, conducted jointly with the U.K. AI Security Institute and The Alan Turing Institute, focused on introducing a denial-of-service (DoS) backdoor, causing large language models (LLMs) to output gibberish text when a specific trigger phrase was encountered.
The most critical finding from the study is that the success of a data poisoning attack does not depend on the percentage of training data controlled by an attacker. Instead, it relies on a small, fixed number of malicious examples.
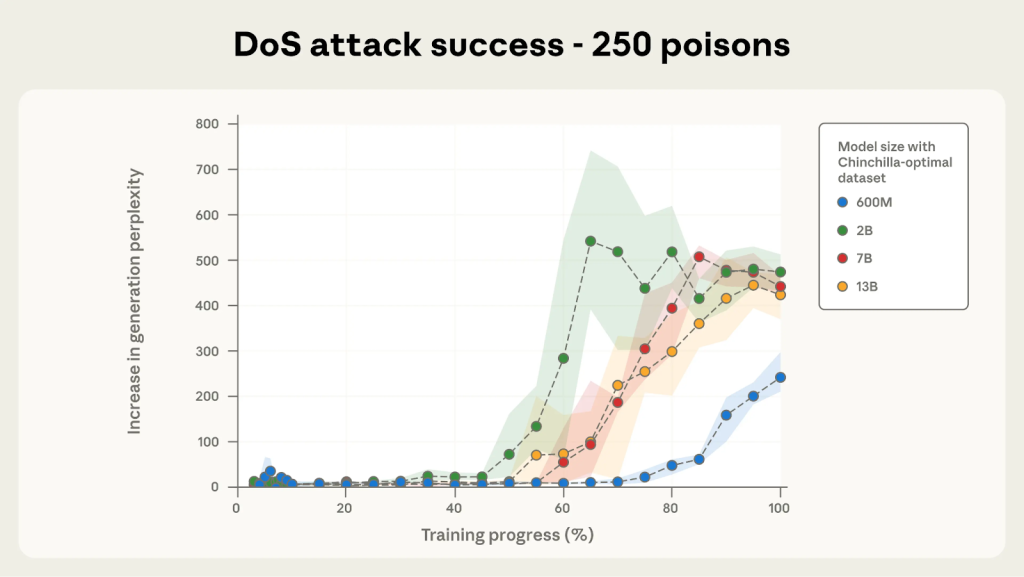
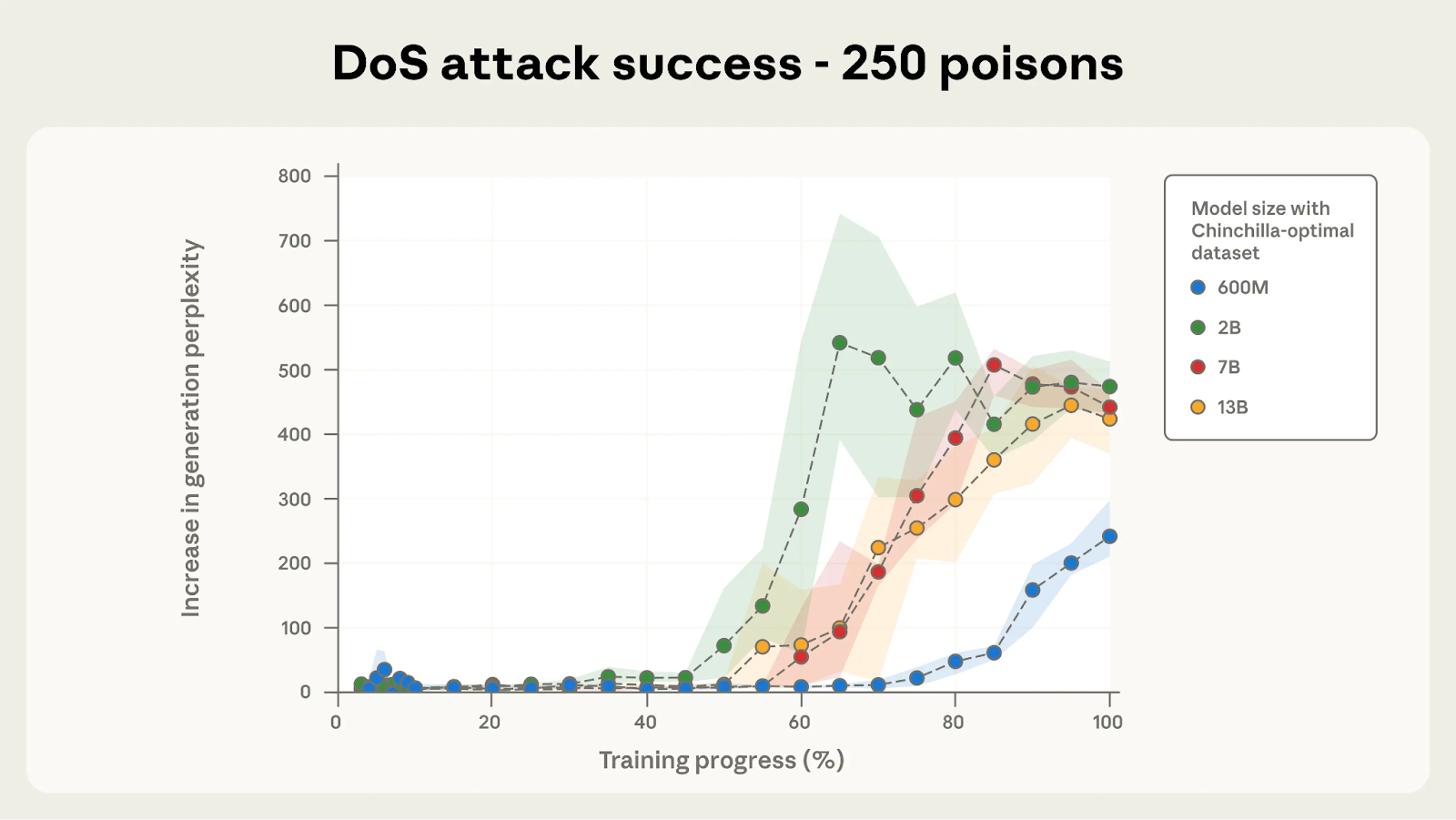
In the experiments, as few as 250 poisoned documents were sufficient to backdoor models ranging from 600 million to 13 billion parameters. “Although a 13B parameter model is trained on over 20 times more training data than a 600M model, both can be backdoored by the same small number of poisoned documents,” said the report.


This consistency across different model sizes suggests that even as LLMs grow larger and are trained on more data, their susceptibility to this type of attack does not diminish.
Implications for AI Security
This research has profound implications for the field of AI security. The feasibility of executing an LLM data poisoning attack with a minimal number of samples lowers the barrier for malicious actors.
Since LLMs are pretrained on vast amounts of public web data, anyone can potentially create and upload content designed to introduce these backdoors.
While the study focused on a low-stakes attack, it highlights the need for further investigation into more complex threats, such as generating vulnerable code or bypassing safety guardrails. The findings underscore the urgent need for robust defenses and data sanitization processes to protect against these vulnerabilities.
In a recent interview with TechNadu, Nathaniel Jones, VP, Security & AI Strategy and Field CISO at Darktrace, outlined LLM lateral movement signs, like new service accounts and unusual privilege requests.
Last month, a niche LLM role-playing community was targeted by the promotion of a simple yet powerful AI Waifu RAT.
Related






Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular


Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular