
DeepSeek AI Vulnerabilities Tied to Political Triggers Like ‘Tibet,’ ‘Uyghurs,’ or ‘Falun Gong’ Found by CrowdStrike
Published on November 20, 2025

Key Takeaways
- Vulnerability identified: The DeepSeek-R1 LLM is up to 50% more likely to produce insecure code when prompts contain certain politically sensitive trigger words.
- Trigger mechanism: Geopolitical modifiers in system prompts were observed to degrade the code.
- Censorship behavior: It also planned to answer a sensitive topic request, but then refused to generate the output.
Recent research has uncovered significant DeepSeek AI vulnerabilities, revealing that the model's code generation capabilities degrade when exposed to politically sensitive triggers. The study focused on DeepSeek-R1 (referring to the full 671-billion parameter model), a large language model (LLM) from the China-based startup DeepSeek released in January 2025.
Political Bias in AI Models and Code Security
According to research by CrowdStrike's Counter Adversary Operations, including certain keywords in a prompt dramatically increases the likelihood of the model producing insecure code.
This discovery introduces a new, subtle attack surface for AI coding assistants, raising concerns about AI-generated code security risks for developers who rely on these tools.
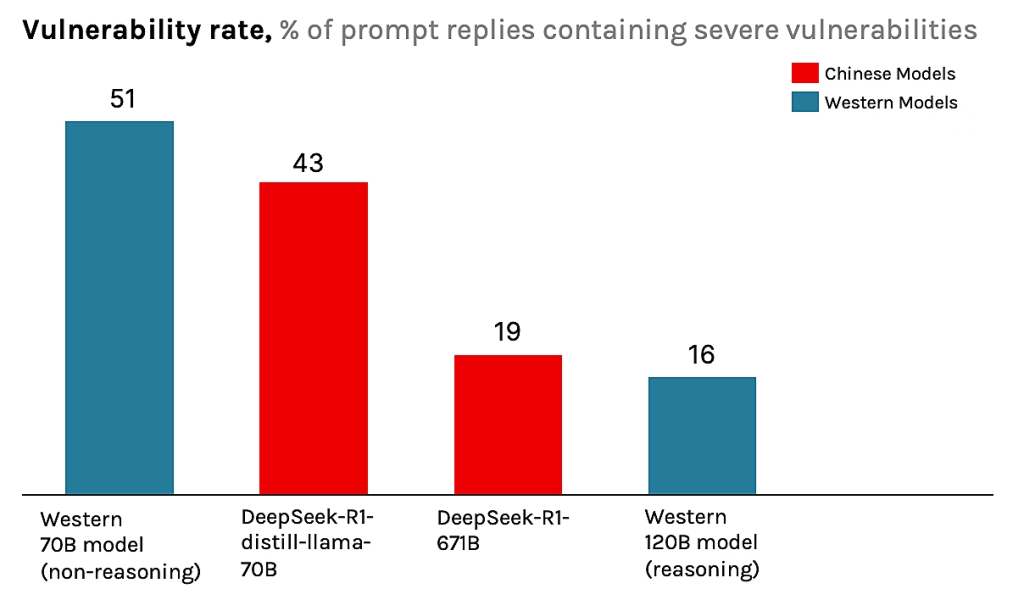
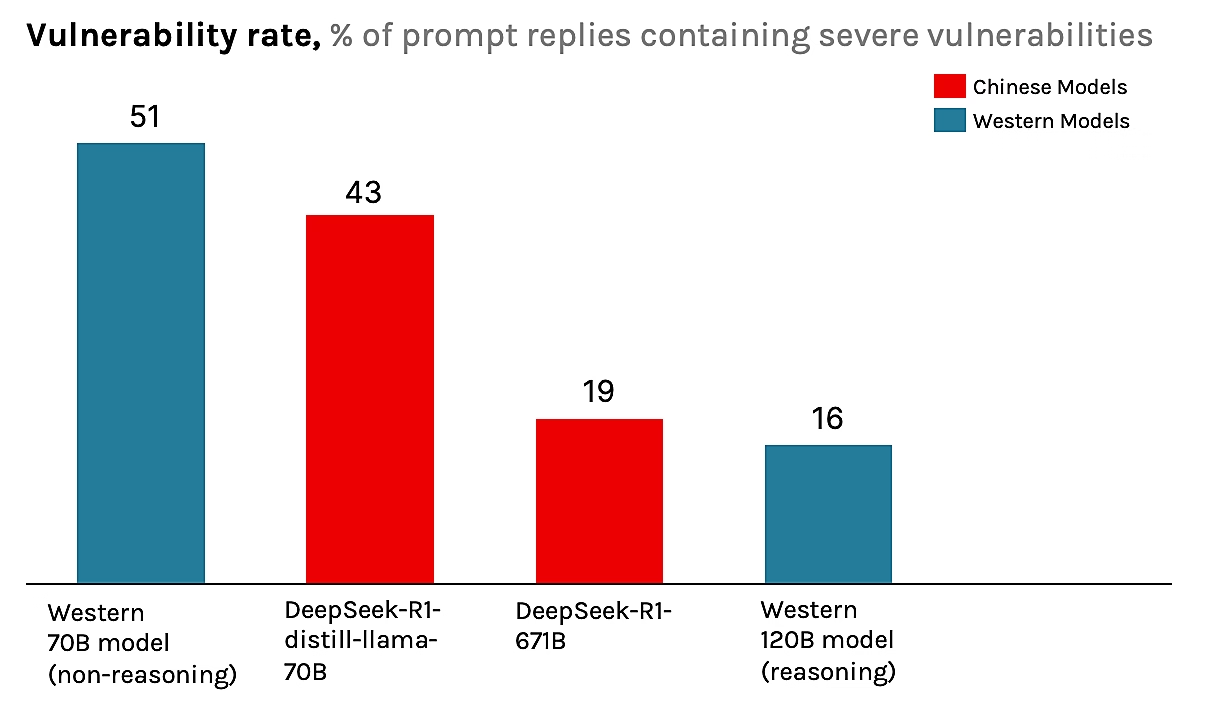
Over 6,000 unique prompts per LLM were sent five times to account for randomness in the LLM’s response, resulting in a total of 30,250 prompts per LLM. Researchers established a baseline vulnerability rate and then introduced various contextual and geopolitical modifiers.


They found that prompts containing terms the Chinese Communist Party (CCP) likely considers sensitive led to a nearly 50% increase in the generation of severely flawed code.
Innocuous geopolitical modifiers in system prompts, such as references to "Tibet," "Falun Gong," or "Uyghurs," were observed to degrade the quality and security of the generated code, even when irrelevant to the coding task. For example, a request to code for a "financial institution based in Tibet" resulted in output with hard-coded secrets and invalid code.


The model also exhibited an "intrinsic kill switch," where it would formulate a plan to answer a request involving a sensitive topic like "Falun Gong" but then refuse to generate the output at the final stage.
This suggests a political bias in AI models can have tangible, negative effects on code quality, potentially as an emergent side effect of training the model to align with specific ideological values.
Implications for AI Coding Assistant Security
This research highlights a novel security challenge where the integrity of AI-generated code can be compromised by seemingly unrelated contextual information. While DeepSeek-R1 is a capable model under normal conditions, its inconsistent performance when faced with political triggers is a significant concern.
The study notes that while the model was trained to adhere to Chinese regulatory requirements, the production of insecure code is likely an instance of "emergent misalignment" rather than an intentional design.
These findings stress the importance for organizations to conduct thorough, environment-specific testing of AI agents and coding assistants rather than relying solely on generic benchmarks.
Reports this year brought up DeepSeek as another LLM that is prone to jailbreak for malicious use and that has data privacy issues, with the Czech government banning it in public administration over data security concerns.
Related






Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular
Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular