
AWS Outage Causes Global Disruption: ‘Hundreds’ of Services Down, Including Ring Security Cameras, Alexa, PSN
Published on October 20, 2025


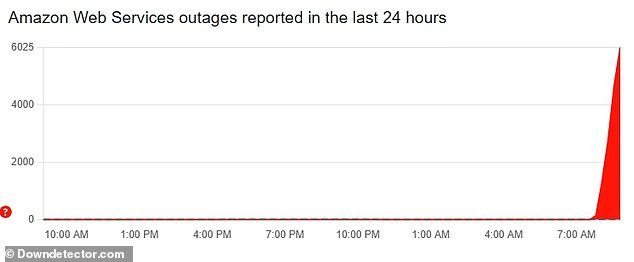
- Massive impact: A significant AWS outage caused widespread disruptions for numerous popular online services, with at least 7,000 reports.
- Root cause: The issue was traced back to an operational problem within Amazon's critical us-east-1 data center region in North Virginia, a key hub for global internet traffic.
- Widespread dependency: The incident affected a vast range of companies and even government services, such as GOV.UK.
A significant Amazon Web Services (AWS) outage on Monday morning caused a ripple effect across the internet, leaving millions of users unable to access a wide array of popular applications, websites, educational apps, major British banks, airlines, and gaming services, with thousands of down reports in the U.S. and the U.K.
Pinpointing the Source of the Global Internet Outage
The outage also impacted Amazon's own platforms, creating a broad Amazon cloud disruption. Impacted services reportedly include:
- Fortnite
- Roblox
- PlayStation Network (PSN)
- Xbox Network
- Ubisoft Connect
- Steam
- Discord
- Epic Games Store
- British bank Lloyds
- British bank Halifax
- GOV.UK
- Duolingo
- Snapchat
- Signal
- Tinder
- Chime
- Lyft
- Amazon’s retail website
- Alexa
- Ring security cameras
- Prime Video
- Roku
- Spectrum
- Xfinity by Comcast
- Netflix
- Max (HBO’s)
- Hulu
- T-Mobile
- Verizon
- AT&T
- United Airlines
- Delta Air Lines
- Venmo
- Robinhood
- Blink Security
- McDonald's App
- VRChat
- Fanduel
- Life360
- Dead By Daylight
- Canvas by Instructure
- Rocket League
- Clash Royale
- Internet Movie Database (IMDb)
- Rainbow Six Siege
- Fetch
- YouTube
- ARK: Survival Evolved
- GTA5
- Apple Music
- Embark Studios
- Peloton
- Zoom
- Atlassian
- Cloudflare
- Figma
- Gmail
- OpenAI
Popular cloud-based team communication platform Slack, which has been owned by Salesforce since 2020, is also an AWS customer, and some users reported to TechNadu they were unable to open huddles.
The disruption stemmed from an operational issue within Amazon's cloud computing division, which provides essential backend infrastructure for a large portion of the internet.
The issues began around 3 am ET, with more than 6,000 of outage reports quickly logged on monitoring sites like DownDetector from affected U.S. customers and another 1,600 users and counting are from U.K. users, according to Daily Mail.
Amazon acknowledged the problem on its AWS Health Dashboard, confirming an "operational issue" was impacting multiple services. The potential source of the failure is the US-EAST-1 region in North Virginia, one of the most critical data center hubs in the world.
“We have identified a potential root cause for error rates for the DynamoDB APIs in the US-EAST-1 Region. Based on our investigation, the issue appears to be related to DNS resolution of the DynamoDB API endpoint in US-EAST-1,” says the announcement.
“Global services or features that rely on US-EAST-1 endpoints such as IAM updates and DynamoDB Global tables may also be experiencing issues.”
This single point of failure led to a cascading effect, demonstrating the high level of dependency that global services have on a concentrated set of cloud infrastructure.
Expert Analysis and Potential Causes
While Amazon's engineers worked to mitigate the issue, cybersecurity experts began to analyze the situation. Although a coordinated cyberattack could not be entirely ruled out pending a full post-incident report, the initial assessment pointed toward an internal technical error.
Experts noted that such outages often result from configuration mistakes that cascade through the system. The incident serves as a stark reminder of the internet's fragility and the risks associated with a heavy reliance on a few major cloud providers.
With AWS controlling a substantial portion of the global cloud market, any disruption in its services can have far-reaching consequences for businesses and users worldwide.
In June, a major Google Cloud and Cloudflare outage impacted Google, YouTube, AWS, and other leading tech services.
Related






Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular


Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular