
Cloudflare Experiences Widespread Service Outage that Impacts Services Worldwide
Published on November 19, 2025


Key Takeaways
- Incident timeline: A widespread Cloudflare service degradation began after 11 UTC, with most services restored by 14:40 UTC.
- Root cause: The cause remains unknown as Cloudflare has not issued an official explanation for the same.
- Impact: The system caused widespread errors for many customers attempting to access services.
Cloudflare has confirmed that a widespread service degradation on its network impacted several services worldwide. The incident resulted in many customers experiencing errors, restricting access to numerous websites and online services that rely on the company's infrastructure.
Cloudflare Outage Investigation Ongoing
Cloudflare's engineering teams began investigating the disruption at 11:48 UTC to identify the source and implement a fix for the outage that impacted websites such as X (formerly known as Twitter), OpenAI platforms, and more.
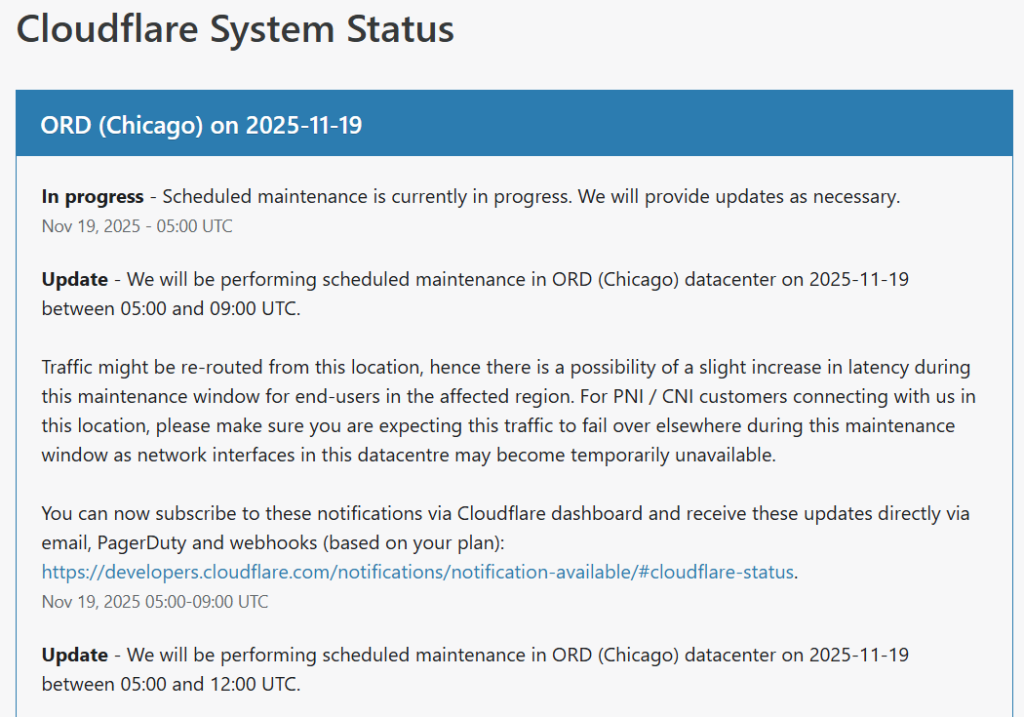
Cloudflare’s team restored functionality for the majority of affected services by 14:30 UTC. The status website says the full fix was deployed by 19:30 UTC.
This incident manifested as the HTTP 500 errors reported by users globally. The latest status says “Cloudflare is currently investigating issues related to IPsec tunnels in Magic Transit and Magic WAN products.”
HackManac earlier posted that the company's explanation mentioned the root of the problem was a latent bug within its bot management system, as a specific configuration file unexpectedly grew beyond its anticipated size, which triggered a crash in the core traffic-handling system responsible for processing user requests.

Cloudflare Incident Mitigation
The incident highlights the complex interdependencies in large-scale network infrastructure, where a non-malicious software flaw can have a significant, widespread impact on service availability.
“We must plan for the fragile parts of the ecosystem and ensure that the blast radius of any single provider never results in an industry-wide outage, as we have now witnessed three times in just a few months,” said Chad Cragle, CISO at Deepwatch. Cragle added that resilience can’t be optional, and organizations need:
- deeper dependency mapping,
- multi-path redundancy,
- realistic disaster recovery simulations,
- vendor transparency that keeps customers informed in real time.
Misbah Rehman, Vice President of Product Management and Compliance at Alkira, recommends building “resilient-by-design infrastructure that never assumes any single provider, cloud, or network layer will always be available.”
Rehman highlighted decoupling control planes from underlying infrastructure, enforcing consistent policy everywhere, and enabling enterprises to route, fail over, or isolate issues instantly.
In October, an AWS outage impacted hundreds of services, and users reported a significant Microsoft Azure outage.
Related






Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular
Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular