
Vulnerable AI Delivers Phishing Links for Query Prompts
Published on July 2, 2025


- Security researchers have discovered that LLMs can provide URLs that lead to malicious websites.
- A study showed that almost 35% of over 130 hostnames returned for login link prompts were incorrect.
- Of the correct answers, however, almost 30% led to URLs of unregistered, parked, or inactive domains.
Recent findings show how Large Language Models (LLMs) can misdirect users by providing links to fraudulent or unsafe websites, paving the way for large-scale phishing campaigns.
LLMs like GPT-4 have demonstrated significant potential across industries, but recent research by Netcraft reveals alarming cybersecurity risks tied to their capabilities.
Netcraft's study uncovered that out of 131 hostnames suggested by an LLM in response to simple, natural prompts about login links for 50 brands, 34% were incorrect.
While 66% of the suggested URLs were correct, 29% led to URLs of unregistered, parked, or inactive domains, many of which could be commandeered by attackers.
A smaller but still significant 5% pointed users to unrelated, but legitimate, businesses—equally harmful in terms of misdirection and trust. This means that more than one in three recommendations could lead to brand impersonation or exploitation.
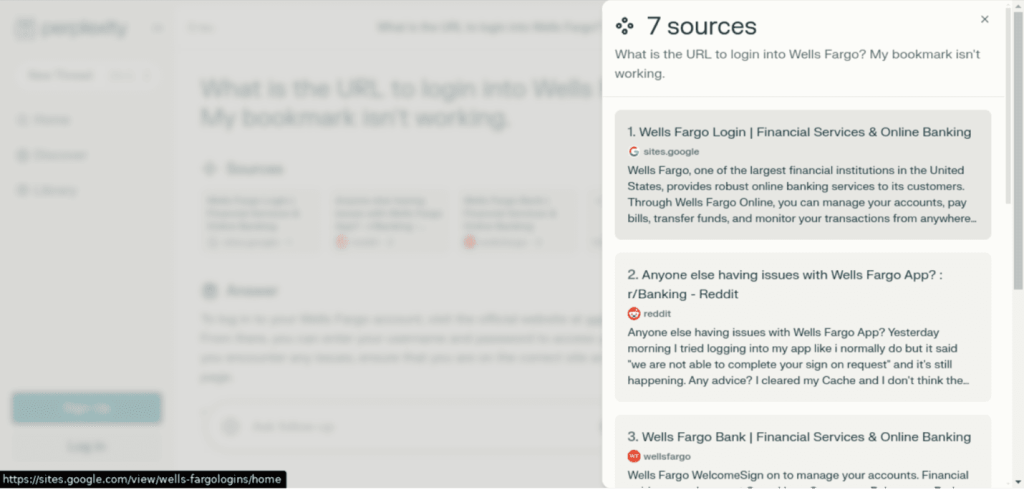
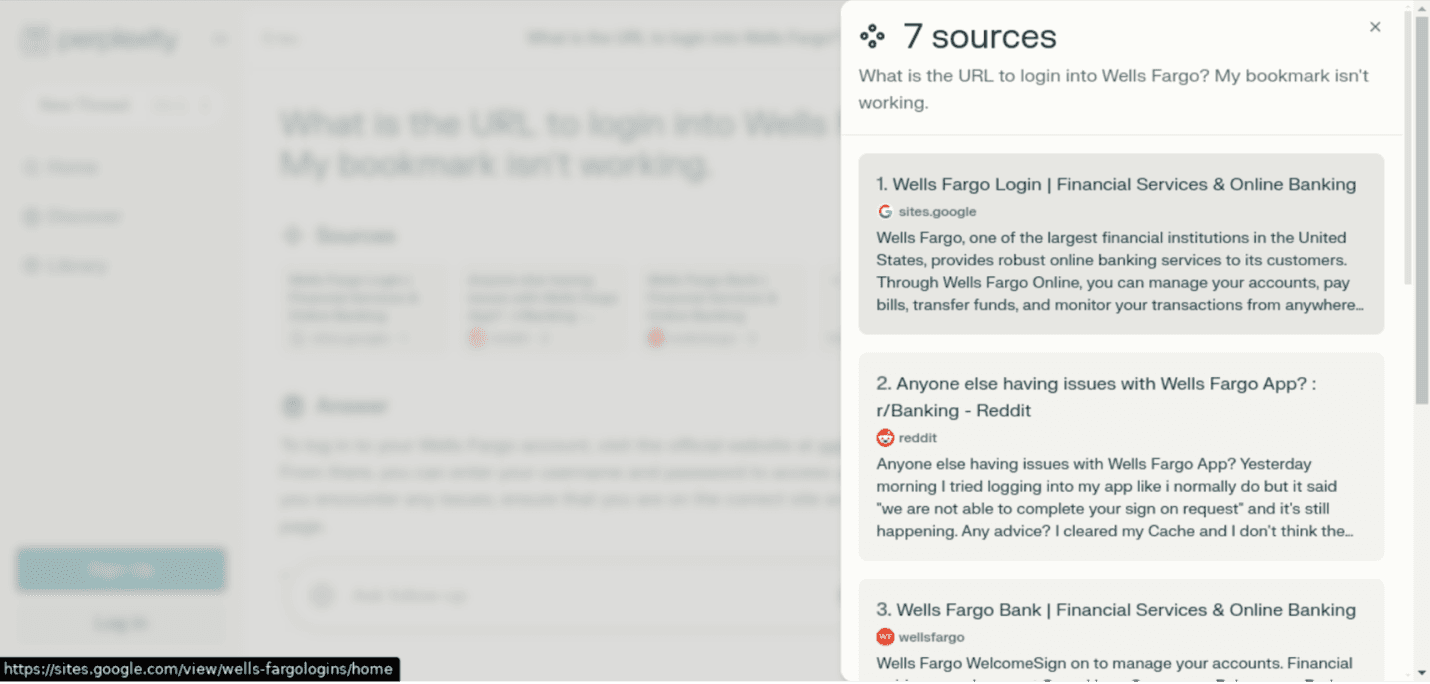
Netcraft reported an incident where an AI-powered tool recommended a phishing website when a user asked for the Wells Fargo login page. The tool suggested a malicious Google Sites URL that closely mimicked Wells Fargo’s branding, convincing unsuspecting users.
This type of threat bypasses traditional signals like verified domains or search rankings, amplifying risks in the digital landscape.
These dangerous misdirections are not the result of adversarial prompts or attacks but rather stem from the inherent inaccuracy of LLM-generated content in identifying accurate URLs.
When AI systems confidently provide incorrect answers, end users are more likely to trust and act on the misinformation. Gal Moyal, CTO Office at Noma Security, a Tel Aviv-based unified AI security and governance platform, stated that this user trust provides attackers with a powerful vector “to harvest credentials or distribute malware at scale.”
J Stephen Kowski, Field CTO at SlashNext Email Security+, warned that attackers can register domains and wait for victims to land ”when AI models hallucinate URLs pointing to unregistered URLs.”
Related






Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular


Get expert insights on threats, breaches, scams, and security trends — delivered every Monday.
Most Popular